The HPC hardware hosted by DCC constitutes general compute and storage resources available to all staff and students at DTU as well as resources dedicated to specific purposes with limited access for prioritized groups of users only. Members of these groups are appointed by the “resource/cluster owner”. Some of the dedicated compute resources are made available to other users (by pooling resources), if not utilized by the prioritized users.
The HPC clusters are managed by the Resource Manager/Scheduler LSF.
More details about the clusters currently available and their hardware specification are available at the following link:
HPC LSF clusters
Those resources are exclusively reserved for batch jobs. See the user guides for more information.
Besides from the HPC compute nodes, “application servers” are provided in the G databar. For more information regarding the Application servers, please consult the following link:
- Application Nodes – General access
And we also manage a number of Accelerators, which is available at the following link:
- Accelerators – Limited access
For the above mentioned nodes, we provide the following HPC Storage resources:
- Parallel Cluster File System (BeeGFS) also called “work1” / 98 TB and “work3” / 142 TB — read more about the Scratch storage here
- Linux Home – 220 TB – read more about the Linux Home storage here
The current DCC HPC architecture is illustrated in the figure below.
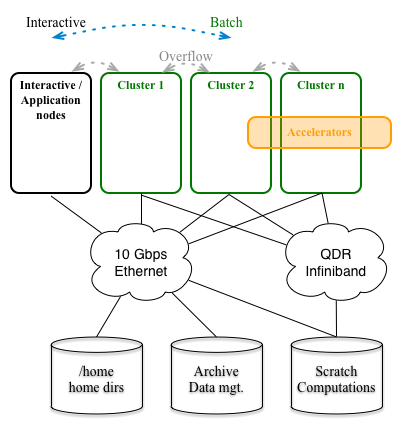
Overview of the DCC HPC setup